
Avec l’avènement du cloud et le besoin croissant de traiter des volumes de données de plus en plus importants, une nouvelle génération de solutions d’intégration de données a vu le jour. Malgré la diversité des outils existants, les entreprises se confrontent toujours aux mêmes problématiques liées à la qualité de données, la documentation ou encore la modélisation. Créé en 2016 par la société dbt Labs (anciennement nommé Fishtown Analytics), dbt compte bien simplifier et accélérer la phase de transformation des données.
dbt, quezako ?
dbt, pour Data Build Tool, est un framework intervenant dans le processus ELT et plus particulièrement sur le « T », c’est-à-dire la transformation des données directement dans la base de données cible (le plus souvent une base orientée Data Warehouse). Un des atouts majeurs de dbt est sa simplicité d’utilisation pour transformer les données puisque reposant sur de « simples » requêtes SQL. dbt peut donc être utilisé à la fois par des Data Engineers mais aussi par des profils moins techniques et plus orientés métier. Fort de ce positionnement, dbt a d’ailleurs défini le rôle de « Analytics Engineer », un nouveau profil Data à la croisée des chemins entre le Data Engineer et le Data Analyst évoluant côté métier tout en étant en charge de la transformation des données dans une optique de valorisation.
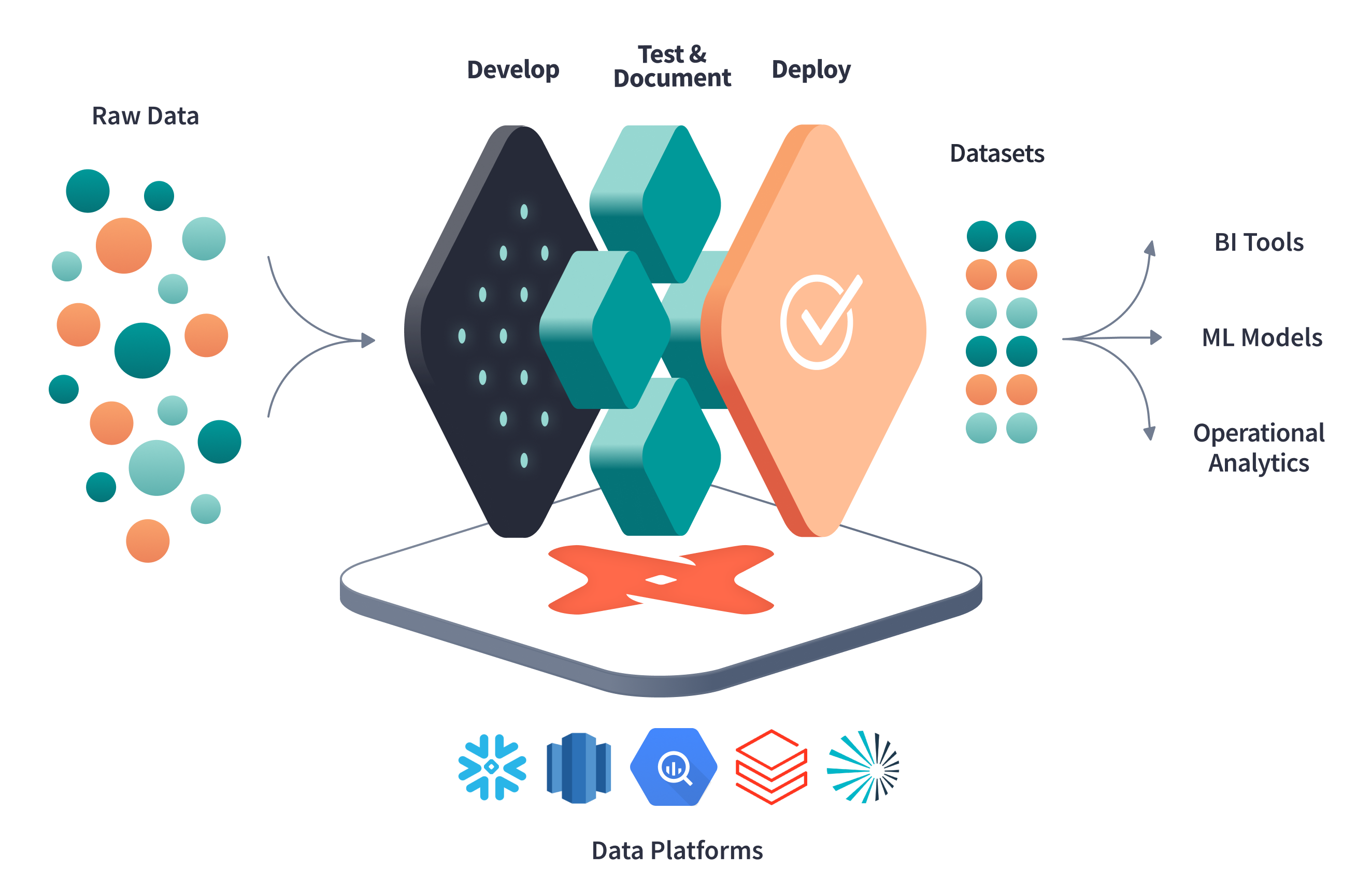
dbt au cœur de la transformation de données
Source : https://www.getdbt.com/
Par rapport aux solutions ETL traditionnelles, dbt se distingue en apportant les bonnes pratiques du software engineering au monde de la Data : tests sur la qualité des données, documentation simplifiée, travail collaboratif, approche CI/CD,…
dbt est disponible sous la forme de deux versions :
- dbt Core : Une version gratuite en mode ligne de commande ;
- dbt Cloud : Une version Cloud payante proposant un environnement de développement intégré et des fonctionnalités avancées.
La version Cloud de dbt est disponible sous forme d’un modèle « freemium ». Il existe plusieurs niveaux de licences donnant accès à plus ou moins de fonctionnalités : nombre de développeurs sur un projet, nombre de jobs concurrents, connexion SSO,…
Par ailleurs, la version Cloud facilite le travail collaboratif en intégrant directement git à son interface de développement. En plus du versioning, la version Cloud de dbt intègre la gestion des environnements (développement, qualification, production) et le scheduling des jobs. dbt s’intègre très facilement à Gitlab, Github ou encore Azure DevOps et permet de mettre en place facilement une chaîne CI-CD complète et efficace.
D’un point de vue connectivité, dbt est compatible avec les principales solutions Cloud du marché : Snowflake, Redshift, Databricks ou encore BigQuery. Mais aussi de nombreux autres formats et de plus en plus de solutions historiques (Teradata, Oracle, MySQL, PostgreSQL,…).
Des projets de transformation de données structures autour du SQL et du Jinja
Un projet dbt est un répertoire structuré contenant un fichier de configuration écrit en YAML ainsi que des modèles. Un modèle est une requête de type « select » enregistrée dans un fichier « .sql » qui sera ensuite transcrite en table ou en vue dans le Data Warehouse.
La particularité de dbt est que le développeur n’a pas à écrire les commandes de DDL (Data Definition Language). dbt se charge d’écrire les « create or replace » ou encore « drop » lors de la compilation du code. dbt propose plusieurs types de configurations possibles en fonction des besoins : modèles incrémentaux pour charger uniquement les nouvelles données, SCD de type 2 pour suivre l’historique des modifications d’une table,…
En plus du SQL, dbt permet d’utiliser Jinja, un moteur de template écrit en Python. L’utilisation de Jinja permet de rendre le code SQL dynamique. Pour ce faire, lors de la compilation, dbt traduit automatiquement les instructions Jinja en instructions SQL valides. Les cas d’utilisation sont nombreux pour améliorer la productivité des développeurs :
- Ajout de boucles « for », de tests conditionnels « if » ;
- Utilisation de variables d’environnement ;
- Création de macros réutilisables ;
- …
Dans le modèle ci-dessous, le Jinja permet d’écrire une commande « Case When » simplifiée en itérant sur une liste de variables définie en amont :
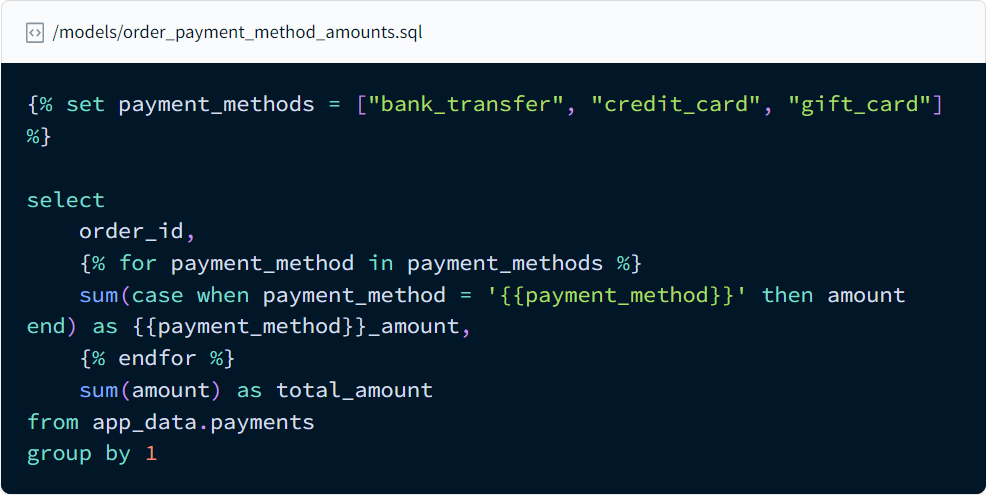
Utilisation du Jinja dans dbt pour simplifier la commande « Case When »
Source : https://docs.getdbt.com/docs/build/jinja-macros
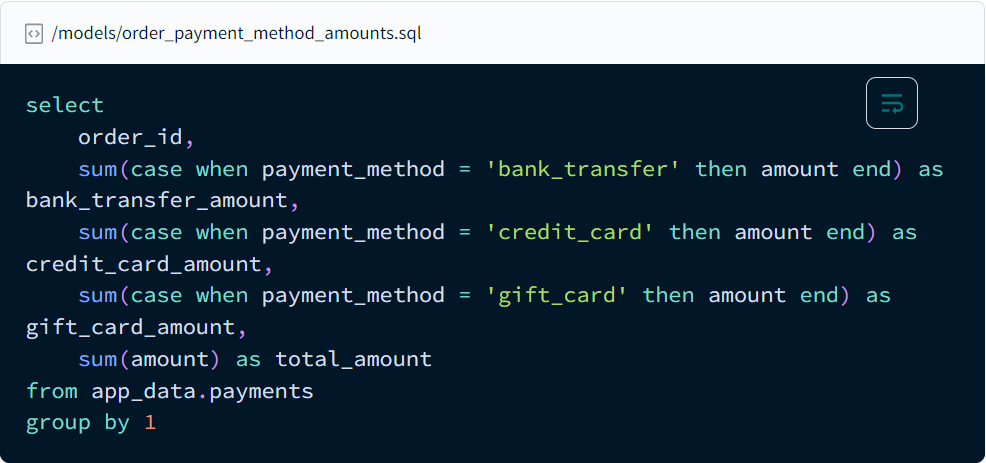
Le code SQL généré une fois la compilation par dbt réalisée
Source : https://docs.getdbt.com/docs/build/jinja-macros
Des données plus fiables grâce au Data Lineage
Une autre fonctionnalité clé de dbt est la gestion des dépendances entre les modèles. Une dépendance est rendue possible via l’utilisation de la fonction Jinja « ref » qui permet de référencer un autre modèle. Cette méthode évite aux développeurs d’écrire le nom d’une table ou d’une vue en dur dans le code.
L’ensemble des appels à la fonction « ref » permet de créer un DAG (Directed Acyclic Graph) avec l’ensemble des nœuds d’un projet et ainsi d’exécuter les modèles dans le bon ordre. Un DAG permet par ailleurs de disposer de la généalogie des données (Data Lineage) en un coup d’œil et de s’assurer que le modèle est modulaire et correctement structuré.
Exemple de DAG (directed acyclic graph)
La généalogie des données est déterminante dans le bon déroulement d’un projet d’intégration de données. dbt apporte les fonctionnalités de généalogie indispensables pour disposer d’une vision d’ensemble et qui sont bien trop souvent absentes ou difficilement exploitables avec les solutions ETL traditionnelles.
Des tests automatisés et robustes pour des données de qualité !
Comme évoqué au début de cet article, une des points forts de dbt est d’apporter les bonnes pratiques du Software Engineering au monde de la Data. Les tests sur les données sont bien trop souvent négligés avec les solutions ETL traditionnelles telles que Talend ou Informatica.
dbt permet de tester aussi bien les sources de données que les données transformées et cela via deux types de tests :
- Des tests génériques définis dans les fichiers de configuration (not_null, unique, accepted_values, relationships) ;
- Des tests spécifiques écrits directement dans des fichiers SQL. Il est par exemple possible de vérifier que les valeurs d’une colonne soient toujours positives ou encore s’assurer qu’un indicateur soit en moyenne compris entre deux valeurs spécifiques.
dbt offre également la possibilité de tester la « fraicheur » des données sources pour s’assurer qu’elles soient toujours à jour.
Les tests peuvent par ailleurs être configurés de différentes manières. Il est par exemple possible de définir le niveau de sévérité (warn, error) en fonction d’un seuil correspondant au nombre de valeurs retournées par les tests.
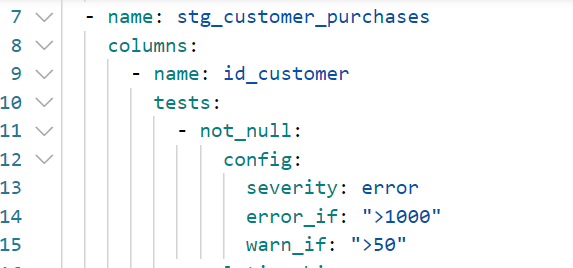
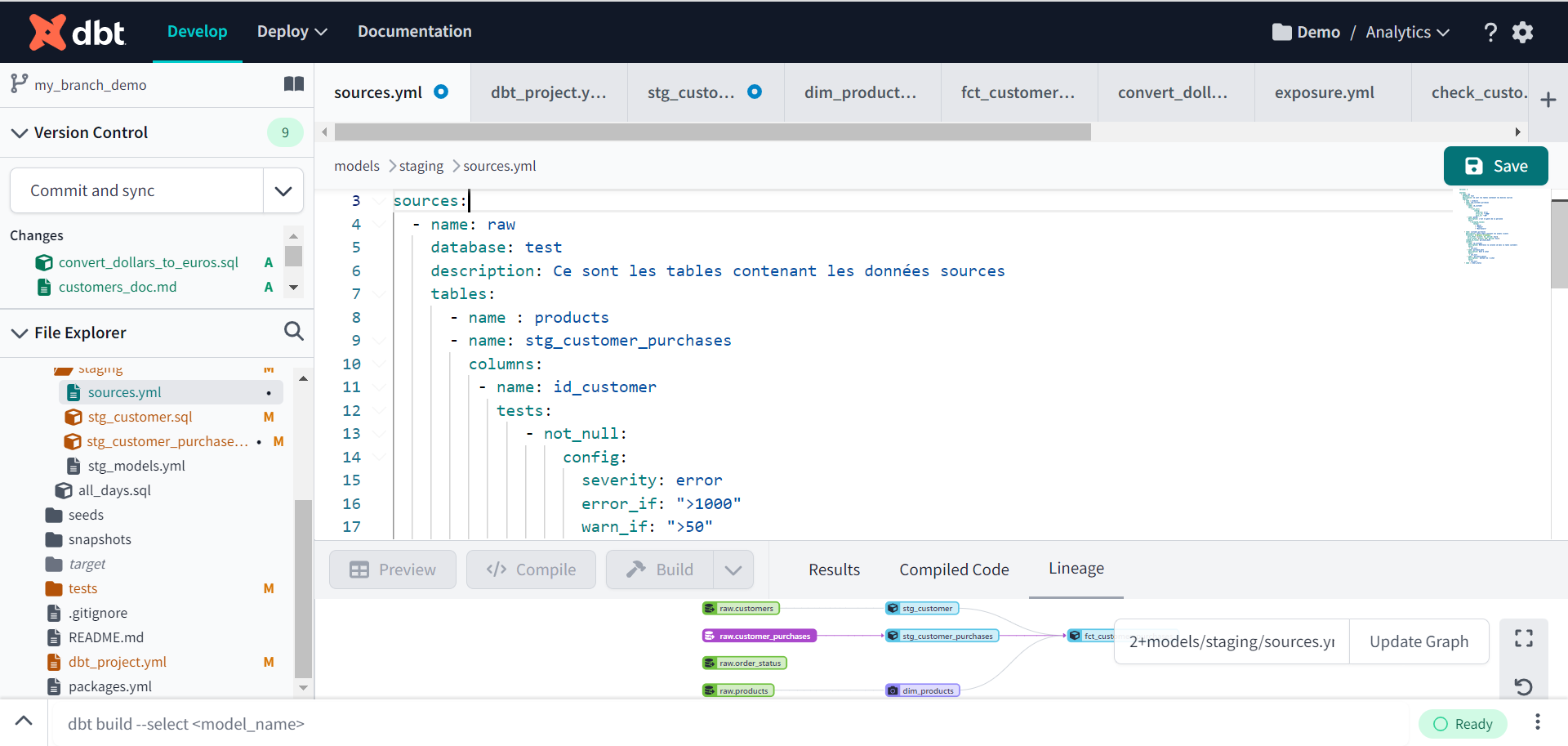
Extrait d’un fichier de configuration dans un projet dbt
La configuration ci-dessus indique qu’un test « not_null » a été appliqué sur la colonne « id_customer » de la table « stg_customer_purchases ». Un bloc de configuration indique que le test retournera un avertissement (warn) si plus de 50 valeurs non nulles sont retournées. Au-delà de 1000 valeurs, le statut du test sera alors en erreur (error).
Une documentation facile à mettre en place
Trop souvent reléguée au second plan (voire la dernière roue du carrosse) dans le cadre des projets Data, la documentation est pourtant un élément fondamental. Elle permet aux utilisateurs métier ainsi qu’aux développeurs de mieux appréhender le modèle de données.
dbt permet de documenter facilement le projet et de rendre cette documentation facilement accessible via une interface Web. La documentation générée inclut des informations à différents niveaux :
- Au niveau du projet : le code SQL des modèles, le DAG, les différents tests,…
- Au niveau de le base cible (le plus souvent, le Data Warehouse) : le type des colonnes, la taille des tables,…
Il est possible d’écrire de la documentation directement dans un fichier YAML via la balise « description » à tous les niveaux de granularité (description d’une source de données, d’une table, ou encore d’une colonne). dbt permet par ailleurs de produire une documentation plus poussée en utilisant des fichiers Markdown.
Une solution déjà populaire avec une adoption croissante
Ces dernières années, l’engouement autour de dbt ainsi que son adoption n’a cessé de croître.
Aujourd’hui, dbt recense plus de 9 000 projets actifs ainsi que 2 000 clients ayant déjà souscrits une licence dbt Cloud. dbt jouit par ailleurs d’une importante communauté avec plus de 25 000 personnes actives sur leur Slack.
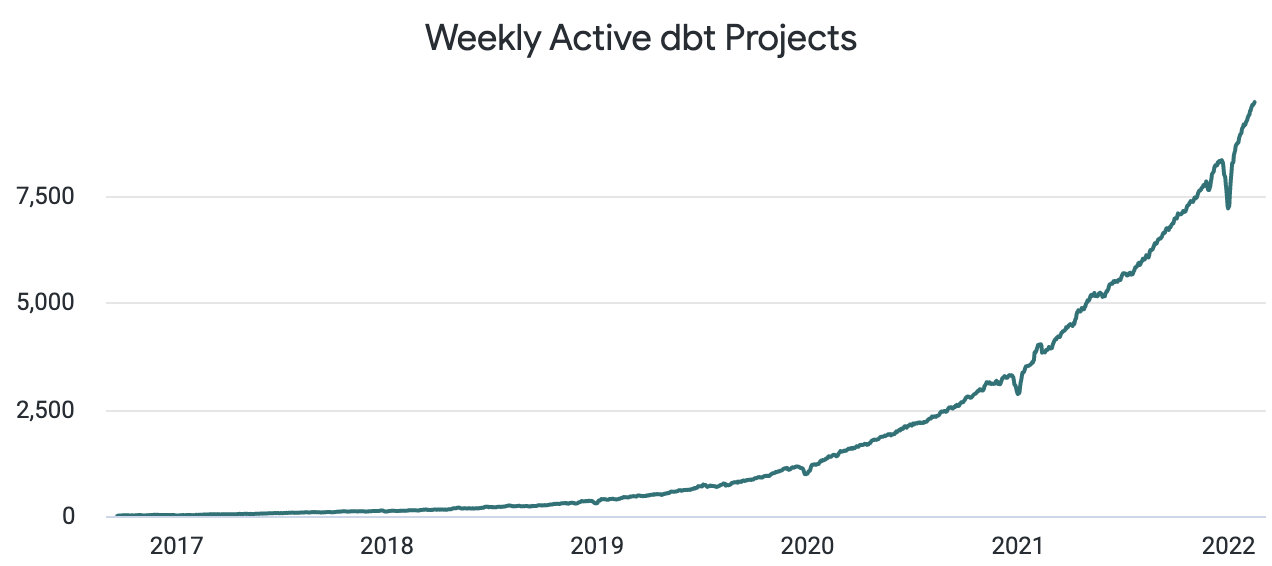
Source : https://www.getdbt.com/blog/next-layer-of-the-modern-data-stack/
De nombreuses entreprises de toutes les tailles, internationales ainsi que françaises (citons, par exemple, Cdiscount ou ManoMano), ont déjà fait le choix d’intégrer dbt au sein de leur architecture Data basée sur le pattern Modern Data Stack.
Preuve de son succès grandissant, en février 2022, dbt Labs a réalisé une levée de fonds de 222 M$ en série D portant ainsi sa valorisation à 4,2 Md$.
Pour conclure
Avec l’essor des Cloud Data Warehouses, l’approche ELT fait un retour en force dans le domaine de l’intégration des données. Dans ce contexte, dbt se trouve être un outil très efficace pour effectuer la partie transformation des données. En proposant une approche standardisée des transformations, dbt permet de garantir la qualité et la fiabilité des données facilitant ainsi la prise de décisions des entreprises.
A l’heure où les entreprises souhaitent construire des plateformes Data composées des meilleures solutions du marché, dbt se révèle donc être un vrai « must have » pour mettre en œuvre une Modern Data Stack (MDS).






