
Fondé en 2012 en Californie, Snowflake est aujourd’hui une plateforme Data Cloud incontournable à l’échelle mondiale.
Avec son architecture révolutionnaire centrée sur un Cloud Data Warehouse (DW) ultra performant et de nombreuses innovations sorties au fil des ans, Snowflake s’est propulsé en un peu plus de dix ans au rang de leader sur le marché des plateformes Data.
Once Upon a Time… in San Mateo
L’histoire de Snowflake commence en 2012, en Californie, lorsque deux ingénieurs français qui travaillaient chez Oracle, Benoît Dageville et Thierry Cruanes, ambitionnent de créer une nouvelle solution pour stocker et exploiter les données.
A cette époque, les solutions d’entrepôts de données les plus couramment utilisées sont Oracle, Teradata ou encore Greenplum. Bien que très populaires à l’époque, ces solutions n’en présentaient pas moins certaines contraintes et limites :
- Une mise en œuvre nécessitant « beaucoup » d’expertise pour être optimale ;
- Une mise en place technique prenant un temps non négligeable ;
- Une maintenance nécessitant de la main d’œuvre spécialisée en nombre et donc coûteuse ;
- Une scalabilité contrainte par l’ajout de matériels physiques ;
- Un système complexe de partage des ressources de calcul.
Le début de la décennie 2010 coïncide également avec l’avènement du cloud. En effet, à cette époque, les trois futurs hyperscalers phares que sont Amazon, Google et Microsoft entament leur hyper expansion. Attirées par la facilité d’utilisation et la quasi-suppression des coûts de maintenance, de nombreuses entreprises commencent à s’intéresser aux technologies Cloud.
Conscients des limites des technologies de l’époque et convaincus par la puissance du Cloud, Benoît Dageville et Thierry Cruanes décident de créer Snowflake, un entrepôt de données basé sur le cloud fait pour le Cloud.
Une architecture novatrice conçue pour le Cloud ou la naissance d’un « Game Changer »
Le succès de Snowflake s’explique en grande partie par son architecture disruptive qui a complètement rebattu les cartes du marché des entrepôts de données. Snowflake dispose d’une architecture hybride et introduit le concept de « share-disk and shared-nothing ». Si les données sont stockées de manière centralisée et accessible par tous les nœuds de calculs, ces derniers sont eux indépendants les uns des autres, garantissant ainsi les performances, la séparation des charges de travail et la possibilité de mise à l’échelle extrêmement souple.
Disponible dans un premier temps via Amazon Web Services, Snowflake deviendra « Cloud Agnostic » au fur et à mesure des années en s’appuyant également sur Microsoft Azure et Google Cloud. L’intégration du Cloud permet à Snowflake d’offrir à ses utilisateurs une scalabilité quasi infinie en termes de stockage et de calcul.
L’architecture de Snowflake est composée de 3 couches distinctes :
- Cloud Services : Une couche de services garante entre autres de l’authentification, la sécurité et la gestion des métadonnées ;
- Query Processing : Une couche dédiée aux traitements reposant sur des « Virtual Warehouses » (VW) ;
- Database Storage : La couche de stockage où les données sont entreposées de manière unique et transverse et accessibles par tous les « Virtual Warehouses ».
Figure 1 : Les trois couches de l’architecture Snowflake
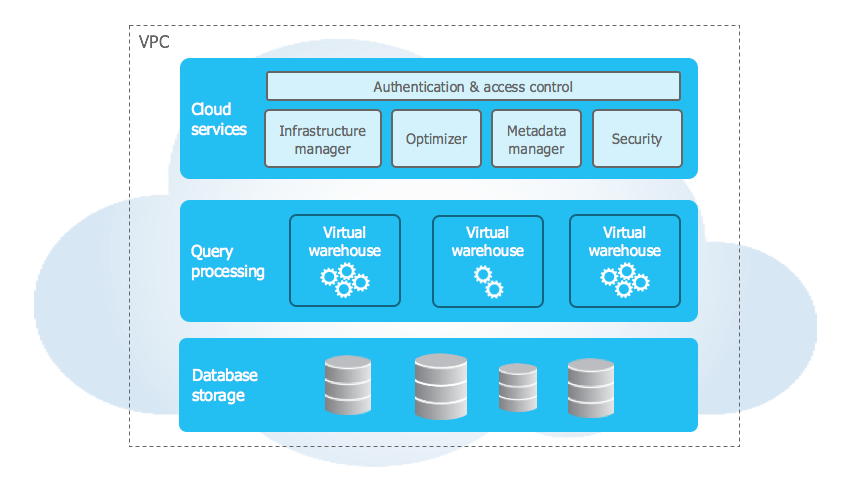
Comme mentionné précédemment, la couche « Cloud Services » regroupe un ensemble de services qui permettent de coordonner les activités au sein de Snowflake. Cette couche permet par exemple de gérer l’authentification des utilisateurs, le contrôle de l’accès aux données en fonction des rôles ou encore la partie optimisation des requêtes SQL.
La seconde couche, celle dédiée aux traitements et appelée « Query Processing », est fondamentale et fait la puissance de Snowflake. Elle permet l’exécution des requêtes grâce à des « Virtual Warehouse ». Etant un cluster de calcul MPP (Massively Parallel Processing), un VW peut donc exécuter plusieurs requêtes en parallèle sur différents nœuds.
Il existe une multitude de tailles pour les VW, sur le même principe que des tailles de t-shirts, allant du XS jusqu’au 6XL. Entre chaque taille, la puissance du VW est doublée (RAM, CPU et SSD). Attention néanmoins à ne pas surdimensionner un VW : l’élasticité de Snowflake permettant de rapidement modifier la taille d’un VW, il est préférable de configurer son VW au plus juste des besoins réels afin d’analyser les performances et la consommation des crédits. En effet, dès lorsqu’ils sont allumés, les VW consomment des crédits Snowflake. Snowflake fonctionnant sur un principe de « pay as you go », le stockage et le temps d’allumage des VW consomment les crédits.
L’autre avantage des VW est leurs indépendances. Il n’y a pas de partage de ressources entre deux VW. Cette indépendance permet de définir des VW spécifiques pour chacun des usages (intégration de données, reporting, self-service, …) et cela sans impacter les performances des VW entre eux.
Figure 2 : Différents « Virtual Warehouses » pour différents cas d’utilisation
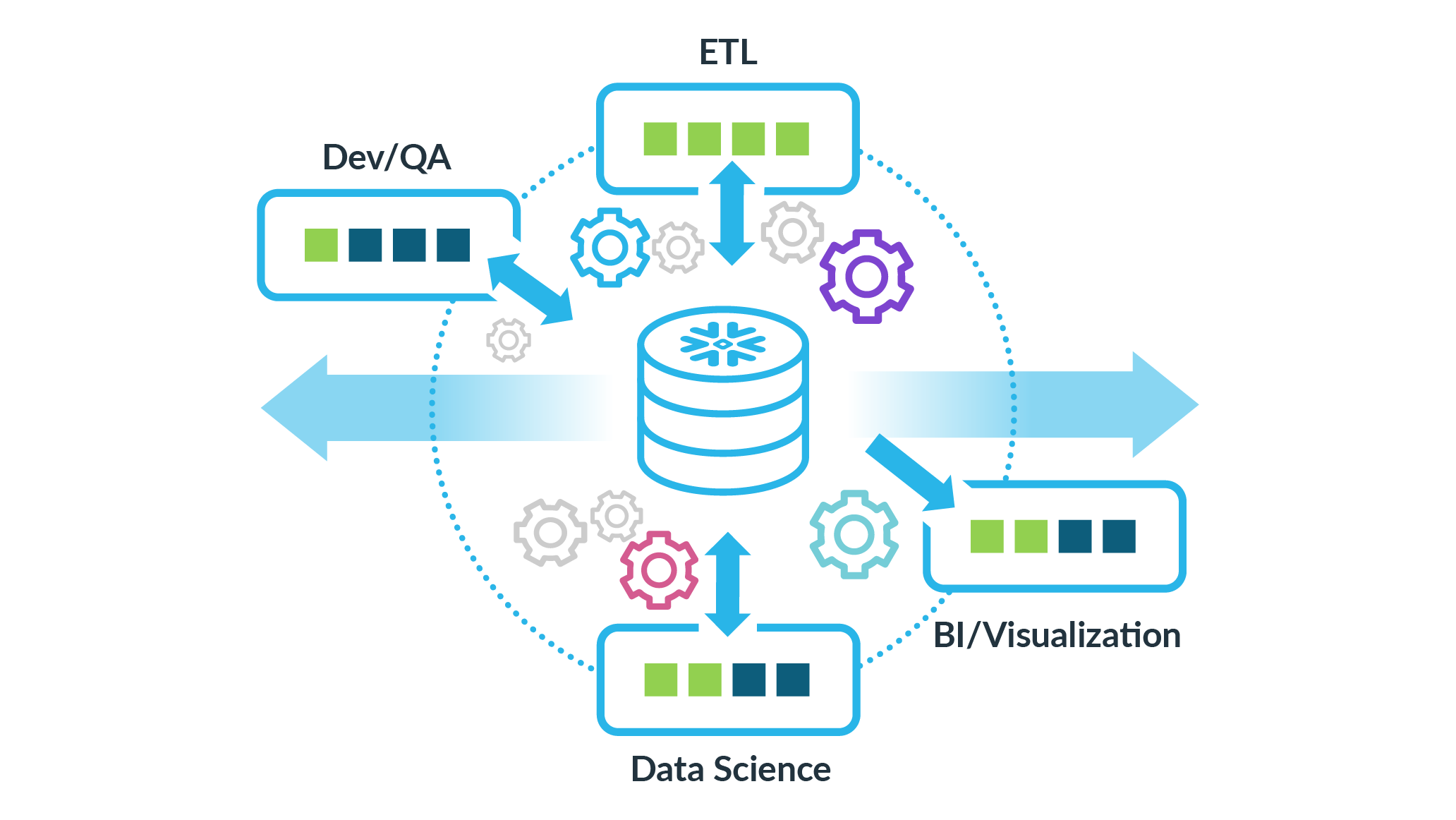
Le schéma ci-dessus illustre parfaitement l’intérêt de la ségrégation des VW. Chacun des usages (ETL, Dev/QA, Data Science et BI/Visualization) disposent de son propre VW avec des configurations plus ou moins puissantes en fonction des besoins. Par exemple, même si un processus ETL consomme beaucoup de ressources via le VW qui lui est attribué, les performances des autres cas d’usages, qui utiliseront les ressources de leurs propres VW, ne seront pas vampirisées.
Cette ségrégation des ressources par usages était jusque-là quasi impossible avec les technologies historiques. Si un usage spécifique (par exemple, l’intégration d’une forte volumétrie de données) nécessitait plus de ressources, l’ensemble des caractéristiques techniques de la base de données devait être augmenté et cela parfois non sans mal et souvent avec un impact financier significatif. Les solutions historiques ne proposaient donc guère d’élasticité et les ressources étaient alors vouées à s’empiler, quitte à être surdimensionnées par rapport aux usages courants afin d’être capable d’assumer les usages ponctuels les plus consommateurs (cf. pic de consommation).
Enfin, la dernière couche de l’architecture est celle dédiée au stockage des données (« Database Storage »). Lors de l’insertion des données, Snowflake va automatiquement compresser et optimiser les données au format colonne en s’appuyant sur le stockage Cloud.
Comme évoqué précédemment, la couche de stockage est complètement décorrélée de la couche de calcul. Cette ségrégation permet une élasticité et une flexibilité totale en fonction des besoins.
Un autre atout clef de Snowflake est sa capacité à gérer nativement de nombreux types de données. En plus des types de données classiques (Numeric, String, Date, …), Snowflake permet l’ingestion de données semi-structurées en tout simplicité. Le type « VARIANT » permet l’intégration des types de données suivants : XML, JSON, Avro, ORC ou encore Parquet. Ces données sont non seulement facilement intégrables mais également consultables simplement à l’aide de fonctions dédiées.
Figure 3 : Requête SQL permettant d’extraire des données JSON grâce à la fonction « Flatten »

Remonter le temps pour restaurer et protéger ses données
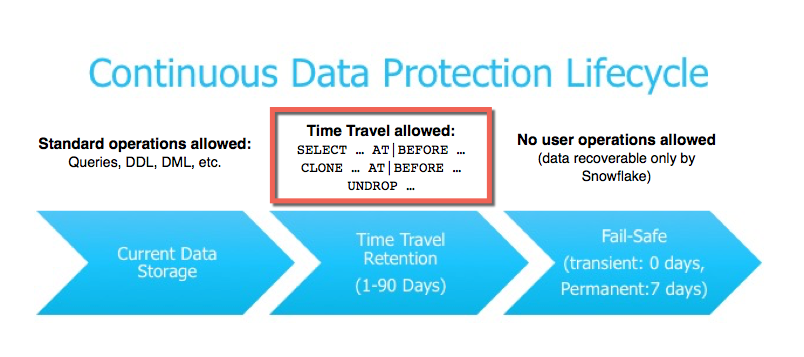
Perdre accidentellement des données en production sans possibilité de les restaurer peut s’avérer catastrophique. Snowflake propose une fonctionnalité de « time travel » qui permet d’historiser automatiquement les données jusqu’à 90 jours en fonction de la licence souscrite.
Pour comprendre le fonctionnement du « time travel », il est d’abord nécessaire de comprendre comment Snowflake stocke les données. Toutes les données insérées dans Snowflake sont automatiquement divisées en micro-partitions. Ces micro-partitions sont des unités de stockages dont la taille est comprise entre 50 et 500 MB de données non compressées. Les données sont regroupées de manière logique dans ces micro-partitions afin d’améliorer le « pruning » (ou élagage) et de garantir des temps de réponses performants grâce aux métadonnées de chaque micro-partition. Les micro-partitions sont « immutables », c’est-à-dire qu’une fois créée, une micro-partition ne peut plus être modifiée. Une requête de mise à jour ou de suppression des données entrainera la création de nouvelles micro-partitions et la bascule d’anciennes micro-partitions en mode « obsolète » mais sans être supprimées pendant une période de « time travel » paramétrable. Au travers de ce mécanisme ingénieux, les micro-partitions permettent une historisation des données.
Le « time travel » s’appuie donc sur ces micro-partitions pour récupérer des données à un instant donné. Les cas d’usages sont nombreux :
- Récupérer des données suite à une corruption des données ;
- Cloner une table à un instant « t » ;
- Restaurer des tables, des schémas ou des bases de données qui ont été supprimés.
Figure 4 : Exemple d’utilisation du « time travel » avec Snowflake

La requête ci-dessus montre un exemple d’utilisation du « time travel » avec Snowflake via le mot clef « AT » et la précision du timestamp qui permettra à l’utilisateur de retrouver ses données telles qu’elles étaient au 1er janvier 2023.
A noter qu’une fois la période de rétention du « time travel » expirée, il existe un ultime moyen de récupérer des données perdues : le « fail safe ». Ce mécanisme est géré directement par les équipes Snowflake qui ont la possibilité de retrouver les données jusqu’à 7 jours après expiration du « time travel ».
Figure 5 : Les différents mécanismes de récupération des données avec Snowflake
Une infrastructure auto-managée et ultra sécurisée
Le succès de Snowflake s’explique également grâce à son infrastructure entièrement managée. Snowflake étant basé sur le Cloud et disponible « as a service », aucune installation n’est nécessaire. De plus, toutes les montées de version sont transparentes et sont gérées par les équipes Snowflake. Robuste, Snowflake affiche une très haut niveau de disponibilité (> 99,99%).
La sécurité des données est une dimension cruciale pour un entrepôt de données. Snowflake met en place de nombreux mécanismes qui permettent de garantir un haut niveau de sécurité :
- Chiffrement des données transmises de bout-en-bout ;
- Plusieurs systèmes d’authentification possibles : mot de passe, MFA, SSO, OAuth, paire de clefs ;
- Whitelisting / Blacklisting d’IPs pour contrôler l’accès à Snowflake ;
- Possibilité de configurer un « private link » afin de sécuriser la connexion entre le VPC Snowflake et le VPC du cloud provider ;
- Re-saisie périodique des données chiffrées ;
- Clés de chiffrement gérées par le client via Tri-Secret Secure pour les données au repos ;
- Sécurité au niveau des colonnes et au niveau des lignes ;
- …
Toujours dans l’optique de faciliter l’expérience utilisateur, Snowflake met en place des mécanismes permettant d’optimiser les requêtes ainsi que les temps de réponses. Par exemple, le résultat de chaque requête est stocké dans le cache de la couche Cloud Services. Ce cache permet de remonter instantanément les résultats d’une même requête exécutée plusieurs fois dans un laps de temps donné.
En conclusion
En seulement quelques années, Snowflake a su s’imposer comme une référence sur le marché des Cloud Data Warehouses. Parmi les milliers d’entreprises ayant déjà adoptées Snowflake, il est possible de citer des grands groupes français tels que Sanofi, Accor et EDF. Son architecture ingénieuse et sa facilité d’utilisation en font un outil de choix pour bâtir une stratégie « Data Driven » efficace.
La concurrence n’est pas non plus en reste et de nouvelles solutions Cloud ont vu le jour ces dernières intentions avec la ferme intention de concurrencer Snowflake et de s’imposer sur le marché des Cloud Data Warehouse.
Au-delà des solutions déjà bien installées sur le marché telles que Google BigQuery ou Databricks, il est intéressant de citer deux solutions :
- Créée en 2019 par les fondateurs de SiSense, la société Firebolt propose un Cloud Data Warehouse éponyme hautement performant et à faible latence ;
- Plus récemment, après une levée de fonds série B de 52,5 M$ en septembre 2023, MotherDuck a lancé sa plateforme Cloud basée sur DuckDB, une base de données open source orientée analytique, et proposant un usage hybride avec l’exécution de requêtes dans le Cloud ou en local.
Porté par de nombreuses levées de fond pour un montant total de 1,4 Md$ et une introduction historique au Nasdaq en septembre 2020, Snowflake a poursuivi son succès en enrichissant progressivement son offre Cloud Data Warehouse afin de proposer aujourd’hui une plateforme Data Cloud.






